
Ever worked with someone so good at their job, you wished you could clone them? The thought process goes something like:
“If only every fraud investigator were as good as Taylor. Every problem she encounters, she can solve quickly. Amid a sea of information, she has an eye for pinpointing what’s critical, and what’s utterly irrelevant. Her work is always 30%-40% better than her colleagues’. And she rarely makes mistakes.”
Taylor might seem powered by magic… but she’s not. She’s powered by an excellent mental model of her domain and maths that’s so complex, it comes across as intuition. What’s happening is that Taylor’s mental model, and the maths underlying it, is better than everybody else’s. It’s an abstract phenomenon with material implications.
Rainbird is a software platform that gives you the tools to copy Taylor’s (or anyone else’s) abstract know-how and represent it visually (kind of like a mind map). That way, a computer can take that knowledge and use it to make decisions in the same domain as Taylor—except 100 times faster and 25% more accurately than her. That is what we call intelligent automation. So, you can have 2 Taylors. Or 100. Or 1000. It’s really up to you. All of them being instructed by Taylor herself.
For the new and improved Rainbird Studio, we set out to accomplish two objectives:
- Make it easier for anyone (really, anyone) to replicate human expertise in machines (we refer to this as building a knowledge map)
- Ensure the process of doing so is pleasant
No code = instant pro
You don’t need to learn the coding language (RBLang) that Rainbird’s engine uses to understand the visual representations of human knowledge. While you could always build a knowledge map in the visual modeller, being able to code gave some users an advantage. Not anymore. Users can now intuitively apply the majority of key features within the visual interface.
When you want to build representations of your knowledge in Rainbird, you do so using concepts (i.e. a kind of thing) and relationships (i.e. how that type of thing relates to other types of things). For example, “Person” might be a concept, “Destination” might be another concept and “Visits” might be a relationship between the two concepts.
So, a “person” “visits” a “destination”—which would help Rainbird understand how people interact with destinations. Every time it then deals with a specific person (e.g. Mike), it knows that it is possible for them to visit destinations (given certain conditions) and can make decisions on that basis. You can then build many relationships and concepts (and more layers of logic and nuance between them all). We’ve moved those deeper layers of modelling right into the visual interface.
A lighter cognitive load
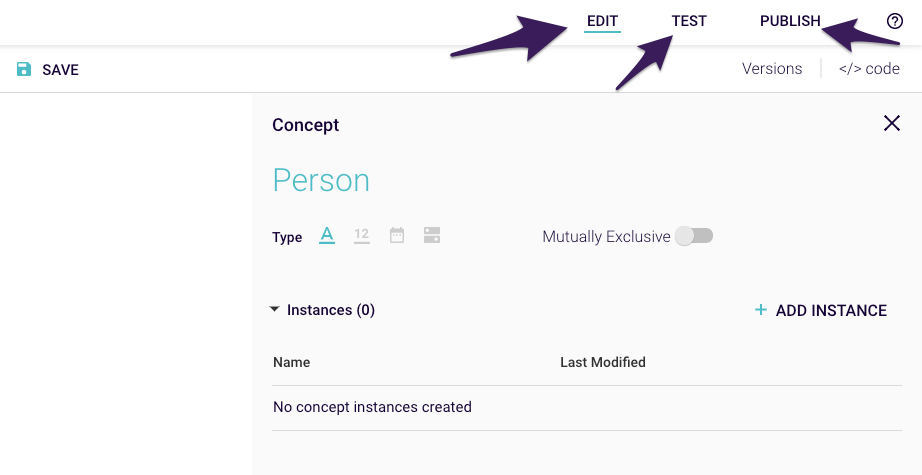
Cognitive overload is a thing of the past with our restructured layout. Our UI overhaul has divided major features into just three sections:
- Edit: where you build models or representations of your knowledge (that look like mind maps)
- Test: where you check that your model is making high-quality decisions, as expected
- Publish: where you unleash your model to make decisions in the real world
This way, the structure and hierarchy of Rainbird features make intuitive sense, rather than hitting you all at once.
Neither a decision tree nor a random forest be
We are often asked, “Is Rainbird machine learning?” Sometimes, Rainbird is even confused with decision trees. It is neither—and it’s important to explain why.
Machine learning refers to systems that can act to give a desired output without being explicitly programmed to do so. A random forest classifier is an example of a machine learning approach that can find patterns in data. And robotic process automation (RPA) refers to the process of programming a computer to take certain actions based on rules expressed as “If this…”, “…then do…” (typically known as decision trees). For example, if “Mike doesn’t have COVID-19 symptoms”, then “he can visit Portugal”.
But these approaches have their challenges. With machine learning, it is difficult for humans to stay fully in control because algorithms find their own patterns in data—and humans don’t always know how or why machines find the patterns they do. So, in sensitive situations—such as credit decisions for minorities or women—we can’t explain why the machine decided one person should get a better credit rate than another. The process is “data-up” (i.e. machines find patterns in data, then impose these on humans), rather than “human-down” (i.e. humans create patterns for machines, which then impose these on data).
With RPA, the decision making process is too linear and unidimensional. You can’t build holistic representations of knowledge—for example, you can’t build a detailed map of concepts and relationships that include COVID-19 risk, job status and destination infection rate. Such that anyone in any situation can consult with the same knowledge map to find out if they can go on holiday. You can only programme one-off steps, for individual scenarios. So, it’s very difficult to build decision trees that can juggle many variables at a massive scale.
And that’s why we’ve focussed on two principles as we improve Rainbird:
- Human-down structure: that is, we start with human knowledge and apply it to data (so that humans can always understand and explain what the machines are doing)
- Non-linear automation: that is, we focus on capturing and codifying knowledge that can apply to multiple scenarios (rather than on steps to be followed in a one-off, isolated situation)
That’s why it’s important that anyone should be able to use Rainbird and our focus is on knowledge representation (not simply the automation of steps). If you’d like to see how the new Rainbird can support your automation agenda, just request a demo.